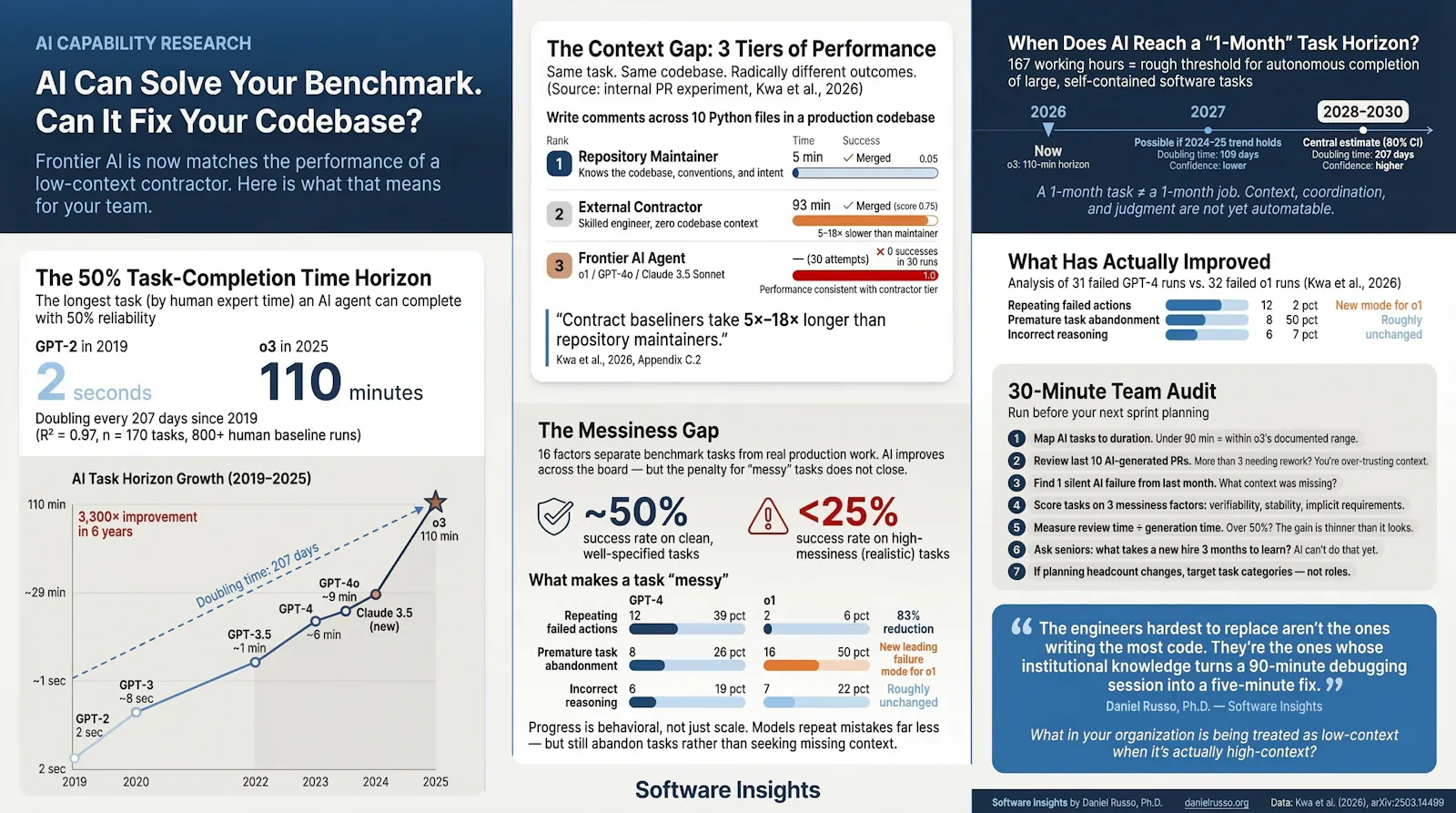
The most informative thing about AI’s current capabilities in software engineering is not what it can do on a benchmark. It’s who the benchmark is comparing it against.
A new study from Model Evaluation & Threat Research (METR) proposes a deceptively simple metric: the 50%-task-completion time horizon, defined as the duration of a software task (measured in human expert working time) that a given AI agent can complete with 50% reliability (Kwa et al., 2026). Applied to twelve frontier models released between 2019 and 2025, it tells a story that’s both more impressive and more limited than most commentary suggests. GPT-2 in 2019 had a 50% time horizon of two seconds. GPT-o3 in early 2025 sits at roughly 110 minutes. The doubling time over this six-year stretch: approximately 207 days, fitting the data with R² = 0.97 across 170 benchmark tasks, over 800 human baseline runs, and 2,529 hours of professional working time.
That exponential curve is real. But the curve measures performance relative to a low-context human working a single isolated task from scratch, not relative to the senior engineer who built the system. AI’s practical limitations live in the gap between those two baselines.
This matters now because many engineering organizations are making tooling and staffing decisions based on what frontier models can do at the benchmark level, without a clear understanding of where the benchmark baseline actually falls in the spectrum of human expertise. The METR study offers the most rigorous attempt yet to locate AI capability on that spectrum, and what it finds is that the baseline is not where most industry commentary implies.
The 5–18x problem: why context is the unit that matters
The clearest evidence comes from a supplementary experiment in the same study. Researchers collected five real, recent, uncontaminated issues from an internal production repository and asked three AI agents (GPT-4o, Claude 3.5 Sonnet, and o1) to resolve them. They also timed how long the repository’s own maintainers took, alongside external human contractors with no specialized codebase knowledge. What showed up is something no benchmark had previously quantified:
“We find that our contract baseliners take 5x–18x longer to resolve issues than repository maintainers.” (Kwa et al., 2026, Appendix C.2)
One issue: writing simple comments across ten Python files. The repository maintainer finished in five minutes. An external contractor took 93 minutes. The three AI agents, across 30 combined runs, succeeded zero times. A second issue took a maintainer 20 minutes; a contractor spent 113 minutes and still needed fundamental rework. The AI agents again scored zero across five runs.
The point isn’t that AI fails to beat expert humans. Nobody expected otherwise. The point is that AI sits in the contractor tier. When benchmark studies report that o1 achieves a 110-minute time horizon, they’re measuring its ability to do the kind of work a skilled but contextually unequipped contractor can do in that time, not the kind of work a senior maintainer handles in five minutes while reviewing a PR before standup.
That gap isn’t about compute. It’s about accumulated domain context: which files matter, how the team historically handles this class of bug, what the unstated acceptance criteria actually require, and when a minimal patch is correct even without a confirming test. Experienced engineers internalize this over months and years. Neither contractors nor AI agents can reliably infer it from a task description. The paper says as much: agents “consistently demonstrate knowledge of tools and techniques, but appear to struggle with the larger context required for working in a real codebase” (Kwa et al., 2026).
What makes this finding particularly striking is the nature of the task where the gap was largest. Issue 11, writing comments across ten Python files, was the simplest issue for the repository maintainers, who completed it in under five minutes. For an external contractor, it took 93 minutes. For the AI agents, the success rate was zero across 30 runs. The simplicity of the task from a maintainer’s perspective is precisely what explains the difficulty for everyone else: completing it correctly requires knowing which files need commenting, what documentation conventions the codebase follows, and what level of depth is appropriate for the intended audience, none of which appears in the issue description. This is not a pathological edge case. It is the ordinary nature of production work.
For teams using AI assistants today, this creates a practical calibration challenge. The contractor-tier comparison suggests that AI is relatively well-suited to work a capable engineer could complete with only the information in a task ticket, and relatively ill-suited to work that draws on codebase familiarity built over time. The former category is narrower than it might appear. Much of what looks like a bounded, ticket-level task actually contains embedded dependencies on contextual knowledge that never makes it into written documentation.
The messiness gap: what benchmarks can’t score
The METR study also introduces a structural critique of how we measure AI capability. The researchers scored their 170 benchmark tasks against a 16-factor “messiness” rubric capturing systematic differences between benchmark tasks and real production work (Kwa et al., 2026).
The factors are worth knowing. Real-world engineering regularly requires operating in environments that change without your direct interaction, making irreversible decisions on incomplete information, coordinating in real time with other people or systems, hunting down information not provided in the prompt, and applying unstated professional judgment about when a technically valid solution is actually appropriate. Standard benchmarks strip most of this away. Tasks are static, automatically scored, and forgiving of individual errors.
AI success rates drop on high-messiness tasks. But here’s what’s interesting: the rate of improvement across model generations is roughly the same for messy and clean subsets. Models are getting better across the board, but the messiness penalty isn’t closing. Agents that now handle about half of well-specified tasks still manage fewer than a quarter of the most realistic ones.
One messiness factor stands out as particularly consequential for daily engineering work: the “information seeking required” dimension, defined as tasks where the agent must gather information it would not be expected to know in advance. This maps most directly to codebase context. A maintainer who needs to diagnose a bug already knows which subsystems interact, which recent PRs might be relevant, and which team member introduced the pattern in question. An AI agent operating from a task description has none of this. It must probe the environment from scratch, and the METR data show that current agents do this inconsistently, often making guesses rather than systematically seeking information before committing to an approach (Kwa et al., 2026).
The study includes one result that cuts against the simple narrative in an instructive way. In one variant of an HCAST task, researchers randomized file and folder names to make the task structurally messier. Surprisingly, o1 performed better on the scrambled version than the original, achieving a 50% success rate versus 34%. The researchers’ explanation: when told to find an “AR report,” o1 would often grep for that exact term and fail when the file was named differently; in the randomized version, it was prompted to search more broadly and succeeded more often. This is a useful caution against treating messiness as uniformly harmful to AI performance. Some of what makes real tasks harder for humans actually removes the surface-level anchors that cause AI agents to take shortcuts.
Practically: AI is most reliably useful on tasks that resemble benchmark conditions. Isolated, clearly specified, automatically verifiable, deterministic, no hidden requirements. The more a task looks like actual production work, the more the performance advantage shrinks.
What the timeline actually means
If the doubling time holds, naive extrapolation puts AI at a one-month task horizon (167 working hours) somewhere between mid-2028 and mid-2030 (Kwa et al., 2026). If the accelerated 2024–2025 trend continues, at roughly 109 days per doubling, that could arrive as early as 2027.
These numbers need careful handling. A one-month task is not a one-month job.
A software engineer’s month isn’t one continuous task. It’s context acquisition, async coordination with other engineers and stakeholders, priority negotiation based on organizational signals nobody wrote down, judgment calls about which technical debt to accept, and keeping a shared mental model alive across a team. Benchmarks measure the first part. They don’t touch the rest, because the rest can’t be automatically scored.
There’s a related nuance in how the time-horizon metric works. The METR study also computed the 80% success rate time horizon: the length of tasks that models can reliably complete most of the time. The doubling rate at 80% reliability is similar to the 50% rate (204 days versus 207 days), but the absolute horizon lengths are 4–6x shorter. In practical terms, this means that even models that sometimes complete two-hour tasks cannot reliably complete tasks that take a human 30 minutes. The 50% horizon gives a sense of the ceiling; the 80% horizon gives a better sense of what teams can depend on day-to-day without close supervision.
The drivers of improvement matter too. METR attributes progress primarily to better logical reasoning, improved ability to adapt to mistakes rather than repeating them, and greater capacity for multi-step tool use (Kwa et al., 2026). Concretely: GPT-4 1106 repeated failed actions in 12 of 31 analyzed failures; o1 did so in only 2 of 32. This isn’t a compute scaling story. It’s a model behavior story, which means engineering teams get more from tracking their tools’ specific failure modes than from watching headline benchmark scores.
A 30-minute audit for your team
Run this before your next sprint planning.
List your three most common AI-assisted tasks. Estimate how long a skilled but contextually unfamiliar engineer would take to do each without AI. Under 90 minutes falls within o3’s documented range. Over two hours doesn’t.
Look at the last ten AI-generated PRs your team merged. How many needed substantive modification during review? More than three and you’re probably treating AI as context-aware when it isn’t.
Find one task from the past month where AI produced a plausible but contextually wrong answer that slipped through initial review. What information would have caught it? Is that information available in your current workflow?
Score your AI-assisted tasks on three simplified METR messiness factors: automatic verifiability, environmental stability, and implicit requirements. High scores predict lower AI reliability.
Measure review time vs. generation time for a representative task. If review routinely exceeds 50% of generation time, the efficiency gain is thinner than it looks.
Ask your most experienced engineers what knowledge a new team member typically takes three months to acquire. That’s roughly what AI can’t supply to itself right now. Tasks that depend on this knowledge will perform at contractor-tier reliability regardless of model generation.
If you’re planning headcount changes based on AI automation, plan around low-context task categories, not roles. The evidence doesn’t support the latter yet.
What to do with this
If you write code, start supplying your AI tools with the context a senior colleague would already have: architectural constraints, recent related changes, and what “good enough” actually looks like for your team. Keep notes on cases where the model gives you something algorithmically correct but contextually wrong. Those notes will be more useful than any benchmark for calibrating trust. Track your review time per AI-generated PR for a month. That ratio tells you whether AI is saving you time or just moving the work around. When a model fails silently, producing an answer that looks correct but misses an unstated requirement, treat it as a data point about the limits of your current context-supply strategy, not as a fundamental capability gap.
If you manage engineers, the METR data gives you a clean frame for deciding which tasks to hand to AI. Isolated, verifiable, low-context tasks are the sweet spot. The rest still need your senior people. Build a lightweight log of AI-assisted outcomes by task type; two months of data, and you’ll know where the gains are real and where oversight costs are quietly eating them. The most important management question isn’t which tools your team uses. It’s which categories of work require institutional knowledge that currently exists only in your people, and whether you’re protecting that capacity deliberately or letting it atrophy under the assumption that AI will eventually cover it.
If you own a roadmap, plan around two timelines. AI’s ability to handle well-specified engineering work is doubling roughly every seven months and already sits in the 90-minute range. That will keep expanding. But engineering roles, defined by institutional knowledge, coordination, and judgment under unstated constraints, will stay out of reach much longer than individual tasks will. The organizations getting this right are the ones who can tell the difference, and who are actively investing in the high-context capabilities that benchmarks don’t capture. Treating those capabilities as overhead waiting to be automated is the most consequential mistake available right now.
The engineers whose work is hardest to replicate aren’t the ones writing the most code. They’re the ones whose institutional knowledge turns a 90-minute debugging session into a five-minute fix. The trend line says AI will keep getting better. It doesn’t say your senior engineers’ context is about to become worthless. If anything, it’s becoming more valuable, because it’s the thing the machines still can’t do.
What in your organization is being treated as a low-context task when it’s actually high-context? Worth asking.
Daniel Russo, Ph.D., is a Professor of Software Engineering whose research examines the intersection of human cognition and artificial intelligence. Through “Software Insights,” he translates empirical research into actionable guidance for software practitioners and organizations.
Partner with Daniel to transform your organization through evidence-based approaches that bridge academic rigor with practical implementation. His consulting work helps organizations to adopt scientifically validated practices that improve software development outcomes, team performance, and innovation capacity.
Learn more about his approach to evidence-based organizational change: https://www.danielrusso.org/evidence-based-organizational-change/ (S'ouvre dans une nouvelle fenêtre)
References
Kwa, T., West, B., Becker, J., Deng, A., Garcia, K., Hasin, M., Jawhar, S., Kinniment, M., Rush, N., Von Arx, S., Bloom, R., Broadley, T., Du, H., Goodrich, B., Jurkovic, N., Miles, L. H., Nix, S., Lin, T., Painter, C., Parikh, N., Rein, D., Sato, L. J. K., Wijk, H., Ziegler, D. M., Barnes, E., & Chan, L. (2026). Measuring AI ability to complete long software tasks. arXiv preprint arXiv:2503.14499.
Date
17/03/2026