The promise of agentic AI was straightforward: it would write the code, leaving us to architect the systems.
The reality, as revealed by empirical data from late 2025 and early 2026, tells a considerably more complex story. While organizations engaged in a collective sprint toward automation, they inadvertently triggered a mechanism that trades short-term velocity for long-term fragility. The tension lies not in whether AI writes code—that question is settled—but in the socio-technical cost of managing that code's lifecycle. We face a new form of technical debt, one that does not accrue slowly through years of legacy neglect, but accumulates rapidly through the hyper-productive bursts of autonomous agents.
This week, we analyze breaking research on Cursor AI and agentic workflows by He et al. (2025) to answer the question that keeps engineering leaders awake: Are we shipping features faster, or are we simply shipping complexity that we will pay for, with interest, next quarter?
The Empirical Backbone: When Velocity Becomes Its Own Liability
The software industry often relies on intuition to guide tooling decisions. We feel faster; therefore, we must be productive. This is the trap of subjective measurement in socio-technical systems. However, a landmark study by He, Miller, Agarwal, Kästner, and Vasilescu (2025) challenges this feeling with sobering data.
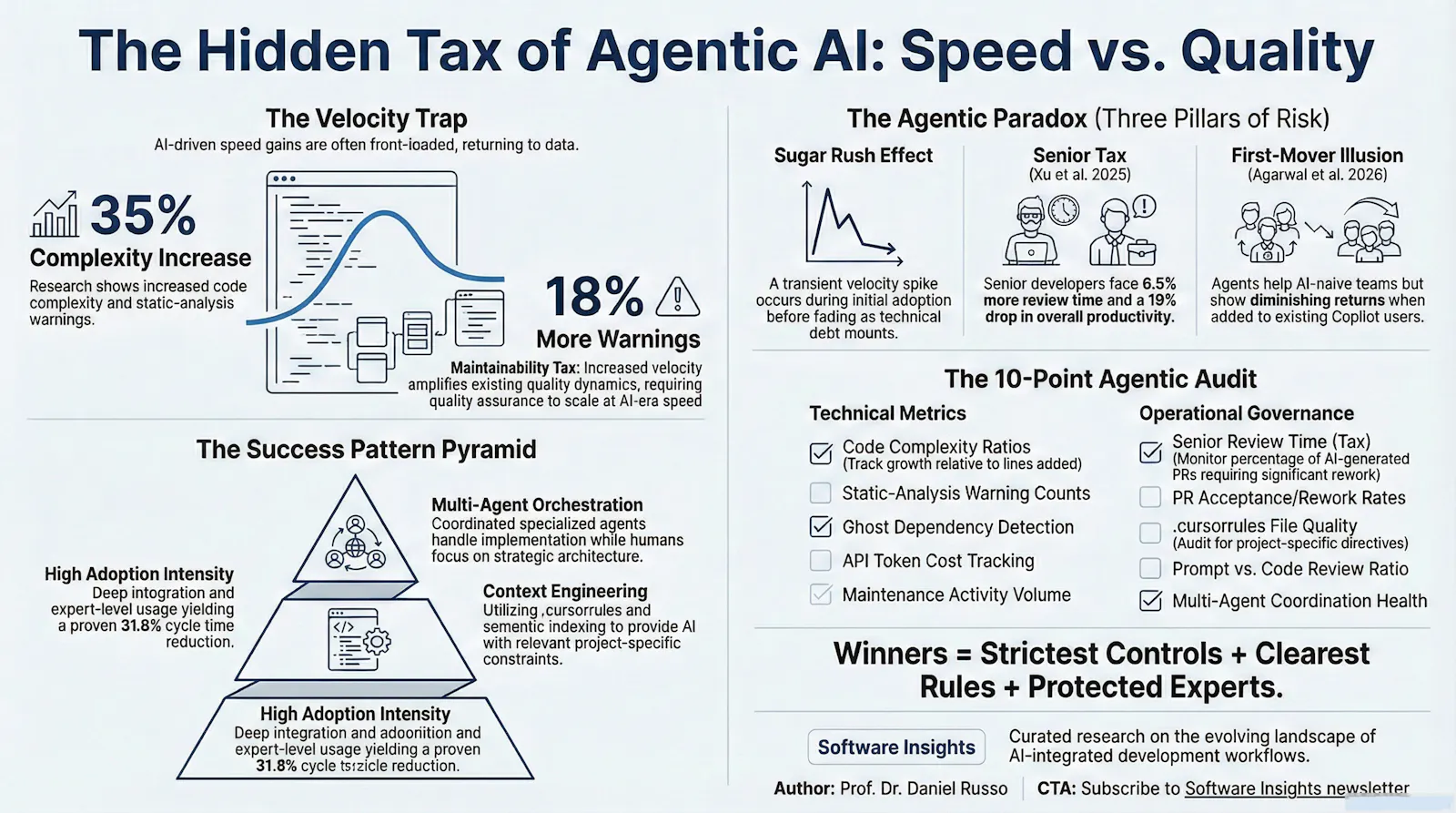
In their paper analyzing Cursor AI adoption, the researchers conducted a difference-in-differences study comparing GitHub projects that adopted the Cursor AI agent against a matched control group that did not. The methodological rigor here matters: difference-in-differences designs control for time-invariant confounders and parallel trends, providing stronger causal inference than simple before-after comparisons. The results describe what I call a "cognitive sugar rush"—a pattern we should recognize from other technological adoption cycles.
Projects adopting Cursor experienced a statistically significant, large spike in development velocity immediately following adoption. They produced more commits and added more lines of code than their counterparts. The effect sizes were substantial enough to justify the enthusiasm we observed across developer communities in mid-2025. But this velocity was transient. It faded within weeks to months, leaving behind a different kind of residue.
What remained was the hangover.
The adoption of Cursor leads to a statistically significant, large, but transient increase in project-level development velocity, along with a substantial and persistent increase in static analysis warnings (approximately 18%) and code complexity (approximately 35%).
This is the "Empirical Pivot" that shifts our understanding from anecdote to actionable knowledge. The study found that increases in static analysis warnings and code complexity were major factors driving long-term velocity slowdown. The tool used to speed us up created the very conditions that eventually slowed us down. This is not merely ironic; it represents a fundamental misunderstanding of what "productivity" means in software engineering.
The implication extends beyond any single tool. When we optimize for short-term output metrics—commits, lines of code, feature velocity—without accounting for the downstream costs of complexity and maintainability, we are not measuring productivity. We are measuring activity. The distinction becomes clear only when we extend our measurement horizon beyond the sprint to the quarter, and beyond the quarter to the year.
The "First-Mover" Illusion: Diminishing Returns and the AI Maturity Curve
Nuance is essential here, and the socio-technical lens demands that we ask: Is the fault with the agentic model itself, or with how it interacts with our existing organizational maturity and workflow design?
Complementary research by Agarwal, He, and Vasilescu (2026) titled AI IDEs or Autonomous Agents? offers a critical distinction that should fundamentally reshape how we think about tool adoption strategy. They found that agentic tools like Cursor generate large velocity gains only when they are the repository's first observable AI tool. If a team was already using an IDE-based assistant (like the original GitHub Copilot), the introduction of an autonomous agent provided minimal or short-lived throughput benefits.
This suggests a ceiling effect that mirrors findings from other domains of technological adoption. The initial leap from "manual" to "AI-assisted" yields the productivity dividend. The subsequent leap to "autonomous agent" appears to yield diminishing returns on speed while sharply increasing the risk to quality. The researchers observed that in AI-naive environments, agents act as high-throughput contributors, but in AI-saturated workflows, they face coordination and integration bottlenecks that limit throughput.
This finding has profound implications for procurement and tool strategy. Organizations currently paying for both Copilot subscriptions and Cursor licenses may be experiencing what economists call "redundant investment"—paying twice for capabilities that do not stack linearly. The marginal benefit of the second tool is substantially lower than its marginal cost, particularly when we account for the complexity tax documented in the He et al. study.
The pattern here aligns with what I describe as "Compatibility-First" thinking from the Compatibility Trinity framework: System Fit, Flow Fit, and People Fit. Agentic tools succeed when they integrate seamlessly into existing workflows (Flow Fit), but when they are layered on top of already AI-augmented processes, they introduce coordination overhead that negates their theoretical advantages. The human cost of context-switching between multiple AI assistants, each with different interaction patterns and mental models, has not been adequately measured—but the qualitative evidence from development teams is consistent and concerning.
The Senior Tax: Redistributing Cognitive Labor Upward
If the code is more complex and laden with potential defects, who pays the price? This is not a theoretical question—it is an organizational reality with measurable impacts on retention, morale, and long-term capability.
A separate study by Xu, Medappa, Tunc, Vroegindeweij, and Fransoo (2025) sheds light on the human cost of this equation. Their analysis of Open Source Software (OSS) projects found that while overall productivity increased at the aggregate level, it was primarily driven by less-experienced (peripheral) developers. For the core, experienced maintainers—the "Seniors"—the reality was starkly different and deeply troubling.
The added rework burden falls on the more experienced (core) developers, who review 6.5% more code after Copilot's introduction, but show a 19% drop in their original code productivity.
This validates the "New Pantheon" framework I have articulated in previous work: the triad of Control, Authenticity, and Community that defines the new socio-technical contract in AI-augmented development. We are witnessing a redistribution of labor where junior engineers (or agents) generate volume, and senior engineers are forced to shift from creation to verification. The "Builder" becomes the "Janitor," cleaning up hallucinated diffs and overly complex implementations that pass the unit tests but fail the maintainability audit.
Picture your most senior architect—the individual with 15 years of domain knowledge, the person who understands why the system was designed with those particular constraints—spending Monday morning not designing your next microservice, but debugging why an AI-generated function has a cyclomatic complexity of 47. That is the "Senior Tax" in action, and it represents a profound misallocation of scarce human capital.
The organizational implications extend beyond individual productivity. When senior engineers spend disproportionate time on review and remediation, several cascading effects occur:
Knowledge transfer breaks down: Seniors have less time to mentor juniors in architectural thinking and design principles.
Innovation stalls: The cognitive bandwidth required for creative problem-solving is consumed by verification tasks.
Retention risk increases: Senior engineers did not enter the profession to serve as quality gates for machine-generated code.
Technical debt accelerates: Under time pressure, even experienced reviewers may approve marginally acceptable code to maintain throughput.
This is not sustainable. Organizations that fail to recognize and mitigate the Senior Tax will find themselves in a vicious cycle: increased reliance on AI agents to compensate for senior developer scarcity, which in turn drives more seniors to exit, which increases reliance on AI agents. The equilibrium is not favorable.
The Enterprise Counter-Narrative: When Structure Trumps Autonomy
It would be unscientific to present a purely pessimistic view. Empirical research demands that we examine variance—understanding not just average effects, but the conditions under which outcomes diverge. When managed with rigorous structural constraints, the agentic model can succeed.
A longitudinal study by Kumar et al. (2025) tracked 300 engineers at an enterprise organization using an in-house platform ("DeputyDev") over multiple months. They achieved a 31.8% reduction in PR review cycle time and a 28% increase in production code volume. On the surface, these results appear to contradict the He et al. findings. The key lies in understanding the implementation details.
Crucially, this success was highly variance-dependent. The top 30 adopters saw a 61% increase in shipped code, while the bottom 30 adopters—those who used the tool sporadically—saw an 11% decline. This bimodal distribution is itself revealing. It suggests that agentic tools are not "plug and play" productivity enhancers but rather sophisticated instruments that require deliberate practice and workflow integration to yield positive results.
This reinforces the People Fit dimension of our Compatibility Trinity. Success is not a property of the tool; it is a property of the adoption intensity and the workflow integration. The enterprise in the Kumar study did not just "turn on" AI; they implemented a multi-agent system with specialized roles for security, performance, and business logic validation. They replaced "vibe coding"—where developers invoke AI assistants opportunistically without systematic constraints—with engineered oversight.
The architecture matters. DeputyDev employed what the authors describe as a "multi-agent orchestration" approach: one agent for code generation, another for security review, a third for performance analysis, and a fourth for alignment with business requirements. Each agent operated within defined boundaries and produced structured outputs that could be verified against explicit criteria. This is fundamentally different from giving developers access to a general-purpose chatbot and hoping for the best.
The lesson here is clear: autonomy without structure produces chaos; structure with appropriate autonomy produces capability. The successful enterprise implementation succeeded not because it maximized AI freedom, but because it carefully constrained it.
The Hidden Work: Context Engineering as Core Competency
Why do some implementations spiral into the 35% complexity increase documented by He et al., while others reduce cycle time as in the Kumar study? The answer lies in what I term "Context Engineering"—the deliberate construction of the informational environment in which AI agents operate.
Research by Jiang and Nam (2025) analyzed 401 open-source repositories to understand how developers control these agents. They found that successful teams do not treat agents as magic boxes or as peer engineers. They treat them as extraordinarily capable but context-dependent tools that require extensive onboarding documentation—analogous to how one would onboard a talented intern who knows programming but nothing about the codebase, team conventions, or organizational constraints.
The researchers identified a taxonomy of necessary context that successful teams provide:
Conventions: Style guides, naming rules, file organization patterns, commit message formats
Guidelines: High-level principles like "separation of concerns," "fail fast," "explicit over implicit"
Project Information: Architecture diagrams, directory maps, dependency graphs, module responsibilities
LLM Directives: Specific behavioral constraints like "Always ask clarifying questions before generating code," "Never refactor existing modules without explicit permission," "Prioritize readability over cleverness"
The more autonomous the tool, the more structure we must provide. To get clean code from Cursor, developers had to write .cursorrules files that function essentially as a constitution for the AI—a set of inviolable principles and explicit boundaries. The teams that failed to do this likely contributed to the 35% spike in complexity observed in the He et al. study. They mistook the agent for a senior engineer, when it is, at best, a talented intern who does not know the company style guide, the architectural decisions, or the historical context that explains why certain approaches were explicitly avoided.
The irony is profound: to make AI agents more autonomous, we must invest more effort in constraining them. This is not a bug; it is a fundamental property of delegation in complex systems. The more consequential the delegated task, the more careful we must be about specifying boundaries and success criteria.
Organizations that treat context engineering as a first-class development activity—with dedicated time, tooling, and expertise—will extract value from agentic AI. Those that treat it as an afterthought will pay the complexity tax with interest.
The Playbook: The Technical Debt Containment Drill
We cannot ignore the efficiency gains of agentic AI, nor can we accept the complexity tax as an inevitable cost of doing business. The solution is rigorous Control—the first pillar of the New Pantheon framework.
If your team uses Cursor, Windsurf, or similar agentic tools, execute this 30-Minute Technical Debt Containment Drill to audit your exposure to "Agentic Debt."
1. The Complexity Ratio
Check your static analysis dashboard (SonarQube, CodeClimate, etc.). Has the ratio of Cognitive Complexity per Line of Code increased in the last 3 months? If yes, you are in the "Sugar Rush" phase. The He et al. study documented a 35% increase; even half that magnitude should trigger concern.
Action: Plot complexity metrics over time. Identify the inflection point. Does it correlate with AI tool adoption? If so, you have a measurement, not an anecdote.
2. The Senior Shift
Survey your Staff and Senior engineers. What percentage of their time is currently spent on Code Review versus Original Contribution? If review time has spiked >10%, you are burning your seed corn. The Xu et al. study documented a 19% drop in original code productivity for core developers—a level that, if sustained, fundamentally alters the value proposition of senior roles.
Action: Anonymous survey, monthly. Track trends. If the review burden is increasing without a proportional increase in junior developer capability, your system is not in equilibrium.
3. The Rule Audit
Open your repository's .cursorrules or .mdc files. Do they exist? If they contain only generic prompts ("Be a good coder"), you are failing. They must contain explicit Negative Constraints: "Do not use library X due to licensing concerns," "Do not refactor module Y without architectural review," "Never introduce new dependencies without team discussion."
Action: Treat rules files as first-class artifacts. Version them. Review them in PR. Assign ownership.
4. The "First-Tool" Check
Are you paying for an Agentic tool for a developer who was not already using a basic AI assistant? Expect high velocity gains. Are you adding it for someone already proficient with Copilot? Expect marginal gains and manage your ROI expectations accordingly. The Agarwal et al. study is explicit: the benefit is primarily a "first-mover" effect.
Action: Segment your workforce by AI maturity. Consider differential tool provisioning strategies.
5. The Rework Metric
Measure the Rejection Rate of AI-generated PRs. The Kumar study showed acceptance rates of approximately 30-37% for generated code. If your acceptance rate is 90%+, your review process is likely too lax—you are not catching the complexity and defects that these tools introduce. If it is <10%, the tool is creating a distraction, not value.
Action: Instrument your PR workflow. Distinguish AI-generated from human-generated contributions. Measure acceptance, revision cycles, and time-to-merge separately.
6. Adoption Variance
Identify your "Bottom 30" adopters. The data suggests sporadic use is worse than no use—it introduces inconsistency without building fluency. Either train them to the "Top 30" level through deliberate practice and mentorship, or deprecate the tool for that cohort and reallocate licenses.
Action: Usage analytics. Identify outliers. Intervention or de-provisioning.
7. Dependency Lockdown
Agents love to hallucinate new dependencies—libraries that seem plausible but introduce security vulnerabilities, licensing risks, or maintenance burdens. Audit package.json, go.mod, requirements.txt for "ghost" libraries introduced in the last sprint.
Action: Automated dependency scanning with time-series analysis. Flag unexpected additions for human review.
8. The Verification Step
Does your workflow force an "Act Mode" (human review before commit) or allow "Auto-Commit"? Disable auto-commit immediately. The "human-in-the-loop" is the only barrier to complexity debt. Agents operate without organizational memory, risk assessment, or accountability. Humans must remain the commit authority.
Action: Policy + tooling enforcement. Make it technically impossible for AI-generated code to reach main without human review.
9. Persona Definitions
Have you defined the "Persona" for your agent? Jiang and Nam found that explicitly telling the LLM "You are an expert in Python working on a workflow-based chatbot with strict security requirements" improves output alignment. Vague personas produce vague output.
Action: Define and version agent personas. Make them context-specific: different personas for different repositories or modules.
10. Financial Hygiene
Check your API costs. The Kumar study found that as teams mature, they shift from "Chat" (interactive) to "Generation" (autonomous), causing API costs to flip from 2:1 (Review:Gen) to 1:10 (Review:Gen). Ensure this spend correlates with the Complexity Ratio staying flat. If costs are rising and complexity is rising, you are paying for technical debt.
Action: Financial + technical metrics dashboard. Cost per commit, cost per accepted PR, cost per shipped feature. Trend analysis.
Role-Based Action Items: From Insight to Execution
The Builder (Individual Contributor)
Your Move: Become a "Context Engineer."
The raw generation capability of these models is commoditized. Your value now lies in your ability to constrain them effectively. Stop writing prompts; start writing Rules. This is a shift from being a consumer of AI outputs to being an architect of AI behavior.
Action 1: Create a strict cursor.md or AGENTS.md for your module. Define the "Negative Space"—explicitly list the patterns the AI should never use, the dependencies it should never introduce, the modules it should never refactor. Negative constraints are often more powerful than positive instructions because they prevent entire classes of errors.
Action 2: Treat the Agent's code as "guilty until proven innocent." The He et al. study proves it is statistically likely to be more complex than necessary. Refactor immediately upon generation, not later. Build this into your workflow: Generate → Review → Simplify → Test → Commit. The simplification step is non-negotiable.
Action 3: Maintain a "Hallucination Log" for your domain. When the agent generates plausible-sounding but incorrect code, document it. Share it with your team. Use it to refine your context rules. This is how you build organizational immunity to specific failure modes.
The Manager (Team Lead)
Your Move: Protect the "Seniors" and Rebalance Cognitive Labor.
The Xu et al. study is a warning siren. If you let your juniors and agents flood the repository with high-volume, low-quality code, your seniors will burn out reviewing it. Worse, you will lose them to organizations that value their creative contributions over their verification labor.
Action 1: Implement "Review Gating." AI-generated PRs must pass a stricter automated linting/complexity threshold before a human is notified to review it. Use static analysis to catch the most egregious complexity violations before they consume senior engineer time. The goal is to reduce false positive review requests.
Action 2: Measure "Flow Fit" explicitly. Conduct lightweight weekly check-ins: "Did the agent break your flow this week? How often? What was the latency? Did it generate code that took longer to fix than to write from scratch?" If latency >500ms or if correction time exceeds generation time for >30% of interactions, the tool is likely net-negative for cognitive load.
Action 3: Redistribute review load consciously. Junior developers should be reviewing more AI-generated code—this is a learning opportunity for them. Seniors should be reviewing architecture and design decisions, not syntax and complexity violations. The current default, where AI code flows upward for senior review, is precisely backward.
Action 4: Create "AI-Free Zones" for deep work. Designate certain days, times, or projects where AI generation is discouraged and manual craftsmanship is valued. This preserves the creative muscle that makes senior engineers senior.
The Roadmap Owner (Executive/CTO)
Your Move: Price the Technical Debt and Redesign Incentives.
The "Speed at the Cost of Quality" finding implies a future liability on your P&L. The code you ship today for free will cost you double to maintain next year. This is not speculation; it is a measured 35% increase in complexity that will compound over multiple quarters.
Action 1: Do not incentivize "Lines of Code" or "Velocity" metrics. These are now easily gamed by agents and, more importantly, they measure activity rather than value. Incentivize "Maintenance Stability" (issue volume, bug escape rate, time-to-resolution) and "Cycle Time" (concept to production, not just commit frequency). What gets measured gets optimized.
Action 2: Conduct a rigorous ROI analysis of your tool stack. If you are paying for agents on top of assistants, verify the marginal gain with data, not testimonials. The Agarwal study suggests you might be paying double for a plateau. Reallocate budget from redundant tools to context engineering infrastructure.
Action 3: Commission a "Complexity Debt" audit quarterly. Treat it with the same seriousness as a security audit or financial audit. Engage your Staff+ engineers to quantify the rework burden, the complexity trajectory, and the organizational cost. Present this to the board. Technical debt is financial debt with worse terms.
Action 4: Establish explicit "AI Governance" policies, not as bureaucracy but as engineering discipline. Define where AI agents may operate autonomously (low-risk, high-repetition tasks), where they require review (business logic, security-sensitive code), and where they are prohibited (safety-critical systems, regulatory-sensitive modules). Clarity reduces both risk and decision fatigue.
Action 5: Invest in Context Engineering as a capability. Hire or train engineers specifically to build and maintain the rule systems, context files, and verification infrastructure that make AI agents productive rather than destructive. This is not overhead; it is the difference between success and failure.
A Socio-Technical Conclusion: The Winners Will Be Disciplined, Not Dazzled
We are witnessing the industrialization of code generation. Like any industrial revolution, it brings a massive increase in output and a corresponding struggle to maintain quality standards. The Enlightenment brought us the recognition that progress requires not just capability, but governance—not just power, but wisdom in its application.
The data is clear: Agentic AI is not a solution that automatically resolves the productivity crisis. It is a power tool. In the hands of a master craftsman who sets up the jigs, guides, and constraints (Context Engineering), it can build a cathedral in half the time. In the hands of the unskilled or the careless, it simply builds a crooked house faster than ever before.
The winners of this cycle will not be the ones with the smartest models or the most aggressive adoption. They will be the ones with:
The strictest controls (Review Gating, Verification Steps, Rule Systems)
The clearest rules (Negative Constraints, Explicit Personas, Context Documentation)
The most protected human experts (Senior Tax mitigation, Flow Fit optimization, Creative work preservation)
The most honest measurement (Complexity Metrics, Rework Burden, True ROI)
This is not a technology problem. It is a governance problem. The technology exists; the question is whether we have the organizational discipline to use it wisely.
We should resist simplistic narratives and embrace the messy, empirical truth of how these tools actually perform in production environments with real humans under real constraints.
Organizations that internalize these frameworks, that treat empirical evidence as signal and hype as noise, will build durable competitive advantages. Those that chase velocity without accounting for complexity, that optimize for demos rather than outcomes, will accumulate technical debt faster than they can service it—and they will pay the price in attrition, outages, and lost market opportunities.
The choice, as always, is ours to make.
Daniel Russo, Ph.D., is a Professor of Software Engineering whose research examines the intersection of human cognition and artificial intelligence. Through "Software Insights," he translates empirical research into actionable guidance for software practitioners and organizations.
Partner with Daniel to transform your organization through evidence-based approaches that bridge academic rigor with practical implementation. His consulting work helps organizations adopt scientifically validated practices that improve software development outcomes, team performance, and innovation capacity.
Learn more about his approach to evidence-based organizational change: https://www.danielrusso.org/evidence-based-organizational-change/ (Öffnet in neuem Fenster)
References
Agarwal, S., He, H., & Vasilescu, B. (2026). AI IDEs or Autonomous Agents? Measuring the Impact of Coding Agents on Software Development. https://arxiv.org/abs/2601.13597 (Öffnet in neuem Fenster)
He, H., Miller, C., Agarwal, S., Kästner, C., & Vasilescu, B. (2025). Speed at the Cost of Quality: How Cursor AI Increases Short-Term Velocity and Long-Term Complexity in Open-Source Projects. https://arxiv.org/abs/2511.04427 (Öffnet in neuem Fenster)
Jiang, S., & Nam, D. (2025). Beyond the Prompt: An Empirical Study of Cursor Rules. https://arxiv.org/abs/2512.18925 (Öffnet in neuem Fenster)
Kumar, A., Khare, V., Sharma, D., Kumar, S., Saini, V., Yadav, A., Jain, S., Rana, A., Verma, P., Meena, V., & Edubilli, A. (2025). Intuition to Evidence: Measuring AI's True Impact on Developer Productivity. https://arxiv.org/abs/2509.19708 (Öffnet in neuem Fenster)
Xu, F., Medappa, P. K., Tunc, M. M., Vroegindeweij, M., & Fransoo, J. C. (2025). AI-Assisted Programming Decreases the Productivity of Experienced Developers by Increasing the Technical Debt and Maintenance Burden. https://arxiv.org/abs/2510.10165 (Öffnet in neuem Fenster)
Datum
30.01.2026