Generative AI is reducing one form of software debt while quietly accumulating two others, and most engineering organisations are still measuring only the one that is shrinking.
The dominant industry framing treats AI-assisted development as a productivity story. Code arrives faster, then refactoring happens automatically, and finally smell detectors and test generators absorb work that previously sat on engineers' backlogs. Every consulting firm with a slide deck has documented some version of that gain. What none of those decks measures is what happens to the layers above the code: the team's shared understanding of why the system behaves as it does, and the externalised rationale that humans and AI agents alike need to reason about safe change.
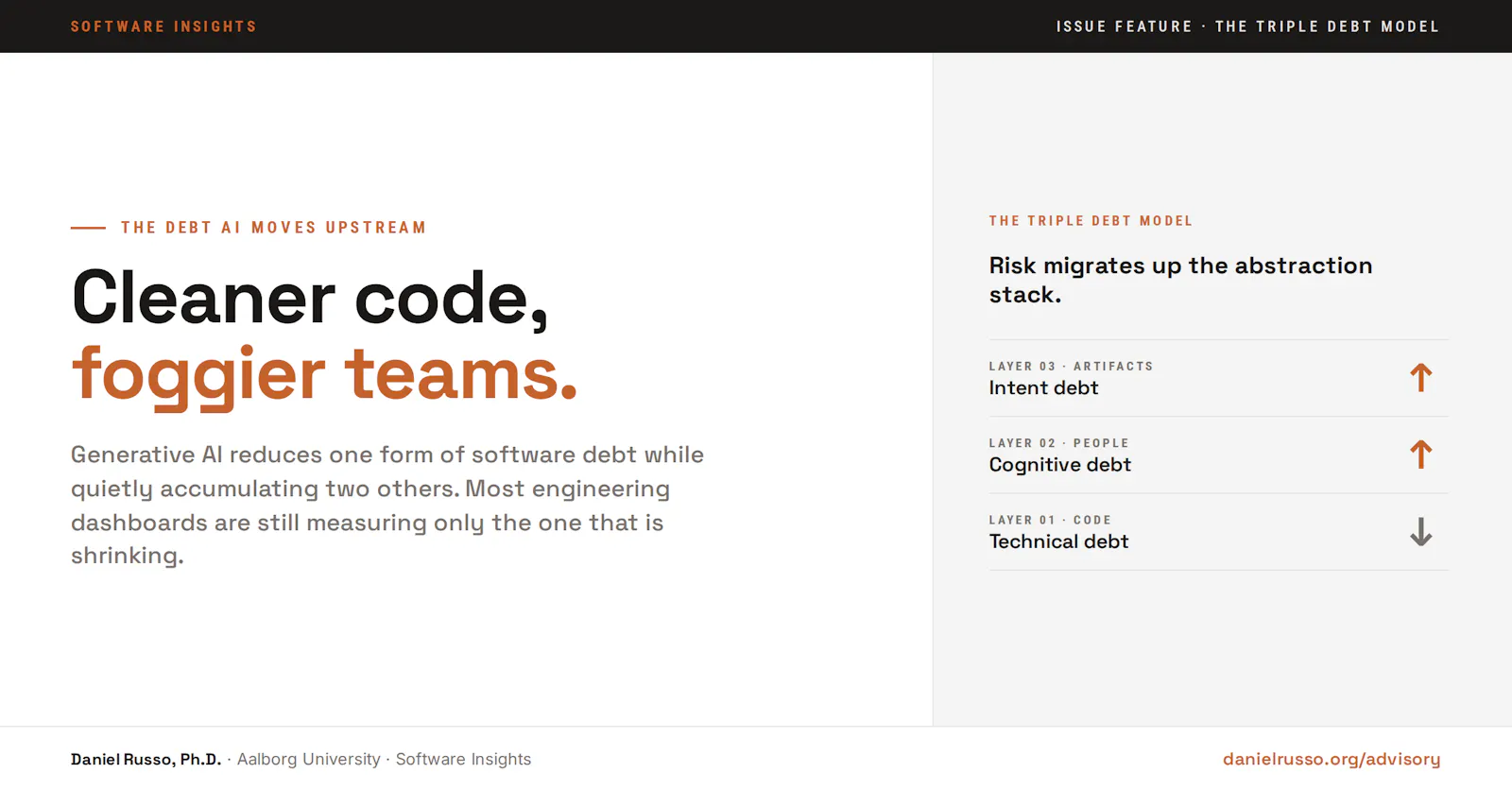
A recent paper from Margaret-Anne Storey at the University of Victoria gives that pattern a name and a structure (Storey, 2026). The Triple Debt Model proposes that software health depends on three coupled layers, each able to erode independently. Technical debt lives in code. Cognitive debt lives in people. Intent debt lives in artifacts. Generative AI is shrinking the first while accelerating the accumulation of the other two, and the conventional metrics most teams report do not register the second-order effects.
Each of the three layers degrades through different mechanisms, responds to different interventions, and produces different operational signatures. A team monitoring only the code layer can show improving metrics across every dashboard while accumulating risk at the layers above. The redistribution is not a future concern, but it is a present condition, and it is the structural reason that AI productivity gains are not translating into the operational improvements organisations expected when they adopted the tools. The argument that follows takes the three layers in turn.
How the technical debt construct decouples
The technical debt construct has been with the field since Cunningham (1993) used a financial metaphor to explain why fast-shipped code accrues future cost. Kruchten et al. (2012) sharpened the construct into a research programme that distinguished principal from interest and modelled the trade-off between delivery speed and maintenance burden. For three decades, the construct did substantial work. It justified investment in refactoring, gave engineers a shared vocabulary for explaining shortcuts to non-technical stakeholders, and informed measurable practices ranging from static analysis dashboards to dedicated remediation sprints.
What Storey (2026) identifies is that the construct, as practiced, conflates three distinct phenomena that AI now decouples in production.
Debt in the code itself: structural shortcuts, weak abstractions, missing tests.
Debt in the team's collective understanding of that code.
Debt in the explicit goals, rationale, and constraints captured in artifacts the team and its agents can consult.
In a pre-AI development regime, these three layers tended to move together. A team that took on technical debt typically also degraded its shared understanding of the affected modules and let intent capture lapse. Reducing one tended to mean reducing all three. The metaphor held.
Generative AI breaks that coupling. Hou et al. (2024) document large language models accelerating refactoring, smell detection, and test generation across multiple production settings. Peng et al. (2023) report substantial productivity gains for engineers using GitHub Copilot, with the largest gains concentrated in routine code generation tasks. The case that AI lowers technical debt accumulation, at least for the visible code layer, is empirically defensible. The system gets cleaner as measured by static analysis. CI pipelines stay green, and test coverage edges upward.
The problem is what happens elsewhere while the code layer cleans up. The team's shared understanding of why the code looks the way it looks does not improve when an agent writes the code. Often, it deteriorates because no engineer was required to build the mental model that produced the artifact. The decision rationale for the agent's output also does not enter any consultable artifact unless someone deliberately captures it, and the very speed advantage of agent-assisted development cuts against deliberate rationale capture.
The result is a divergence: code quality improves while team knowledge and externalised intent both erode.
The three-decade habit of treating debt as a single quantity now produces measurement errors of opposite signs.
Where the cognitive layer erodes
Storey defines cognitive debt as a team-level, project-level property reflecting the erosion of shared understanding across a software system over time, manifesting as increasingly inadequate mental models that developers rely on to reason about the system and change it safely. The construct is grounded in three pieces of foundational work that newer software engineering research has tended to underuse.
Naur (1985) argued that programming is, fundamentally, the construction of a theory of the system in the heads of the people building it. The code is one externalisation of that theory; documentation is another; tests are a third. None of them is the theory itself. When the people who built the theory leave, or when the system grows faster than their mental model can grow with it, the theory degrades even when the artifacts persist. Curtis et al. (1988), in a field study of seventeen large software projects, found that no single developer held the complete picture of any non-trivial system; the theory was distributed across the team in overlapping fragments. Wegner (1987) provided the cognitive science framing for that distribution: groups develop a transactive memory in which each member tracks not only what they know but who else knows what. When transactive memory degrades, the team loses the ability to retrieve its own knowledge, even if individual heads still contain pieces of it.
Hutchins (1995) extended the framing to distributed cognition more broadly. Cognitive processes, in complex socio-technical systems, are properties of people, artifacts, and their interactions, not of individual minds in isolation. A software team's reasoning capacity is a property of the whole configuration: engineers, code, documentation, dashboards, on-call rotations, post-mortems, and the informal channels through which they communicate. Cognitive debt accumulates when any element of that configuration degrades faster than the others can compensate.
The empirical signals that AI-assisted development is accelerating this erosion are starting to converge. Kosmyna et al. (2026) document measurable reductions in neural engagement during AI-assisted writing tasks and report a rebound effect: participants who relied on AI assistance retained less of the produced content and were less able to recall their own reasoning when later asked to defend it. Shaw and Nave (2026) describe a related pattern they call cognitive surrender, in which users of AI-assisted decision tools report inflated confidence in conclusions even when the AI was demonstrably wrong. The combination is the worst possible diagnostic configuration: lower engagement at the moment of production, higher confidence at the moment of review. The mental model that should have been built during production is absent at the moment it is needed for verification.
Storey's redistribution thesis crystallises the implication for software engineering organisations:
Generative AI may reduce technical debt while simultaneously accelerating the accumulation of cognitive and intent debt (Storey, 2026).
That single sentence reframes most of the productivity discourse around AI-assisted development. The gains are real, but they arrive at a layer of the stack that has well-developed instruments and decades of measurement practice.
The accumulation arrives at layers where most organisations have no instruments at all.
Russo's (2026) phase transition argument adds a structural prediction to Storey's diagnosis. Agent-intensive ecosystems undergo a discontinuity at an agent-to-engineer ratio of approximately three to one, after which ecosystem-level behaviour becomes more informative than individual-agent behaviour for understanding the system. Below that threshold, cognitive oversight remains tractable: engineers can still reconstruct the decision logic of agent-generated changes at a reasonable cost. Above it, the system's properties of interest emerge from interactions rather than residing in any single agent or commit, and the team's transactive memory cannot keep pace. The comprehension debt construct introduced in last week’s issue, The Composition Trap (Russo, 2026), names the operational consequence at the artifact level: code that passes automated verification while remaining beyond the team's reproducible decision logic.
The two frames have to be seen as complementary. Storey's cognitive debt names the accumulated team-level erosion of shared understanding observed from inside the cognitive system. Russo's comprehension debt names the failure mode that erosion produces at the artifact level: code that the team cannot mentally simulate. One frame is grounded in distributed cognition; the other in complexity-science emergence. Together, they describe both the cause and the consequence of the same upstream redistribution.
The intent gap that artifacts cannot close
Intent debt is the layer most newly named in Storey's framework, and it is the one that most directly reframes how teams should think about AI agents. Storey describes intent debt as the absence or erosion of explicit rationale, goals, and constraints that guide how a system evolves. Where cognitive debt resides in heads, intent debt resides in the gap between what the team meant to build and what is captured in any artifact a human or an agent can consult.
The construct gains particular force in agent-intensive workflows because AI agents are now first-class consumers of the intent layer. When an engineer holds the rationale in their head, they can apply it implicitly: a code review against an unwritten performance budget still catches the regression because the reviewer remembers the budget exists. When an agent writes the same code, the budget is invisible unless it appears in an artifact the agent reads. The result is a class of failure modes that resemble model limitations but are actually intent-debt incidents masquerading as capability gaps. The agent produces technically correct but pointless solutions, requests extensive rounds of clarification, or burns tokens by reasoning from scratch on questions that a single decision record could have answered. Each of these is a measurable signal of intent debt at the agent boundary.
Storey identifies several diagnostic signatures. Behaviour drift from stakeholder expectations, even when the code is technically correct, points to lost or never-captured constraints. Loss of articulated performance budgets, privacy commitments, and accessibility requirements is a classic pattern: the constraints exist in someone's memory and are honoured when that person reviews changes, but they disappear from the system the moment that person is unavailable. Onboarding cost rises because new engineers and new agents have no documented theory of what the system is for, only of what it currently does. The two are not the same.
The mitigations Storey proposes are of a diverse nature.
Behaviour-driven specifications and tests that capture purpose rather than only verifying mechanics.
Architecture decision records that externalise the why alongside the what.
Domain-driven design vocabulary that gives the team a shared language for talking about constraints.
The shared characteristic is that all of them produce artifacts that are agent-readable in the same way they are human-readable. This is the operational definition of context engineering, i.e., the practice of producing instructions and rationale dense enough that an agent given access to them produces outputs aligned with team intent without needing the rationale to be re-derived in every interaction.
The dual relationship between comprehension debt and intent debt makes the combination useful for diagnostic purposes. Comprehension debt is the team's failure to reconstruct the rationale that an agent produced. Intent debt is the team's failure to externalise the rationale that the agent then has to invent. These are inverse failure modes, and they tend to produce inverse organisational pathologies. Teams with high comprehension debt accumulate change-resistant code that no one wants to touch. Teams with high intent debt accumulate agent failures that the team blames on the model rather than on its own missing specifications. Diagnosing which form dominates is the first step toward choosing the right intervention.
The 30-minute audit
The following diagnostic surfaces the three debt types in a single team session. Each item is designed to take a few minutes; the full list runs in roughly thirty.
1. Pull a sample of ten AI-generated commits merged in the last sprint. For each, ask the on-call engineer to reconstruct the decision logic in under five minutes. Count how many they cannot. The fraction is your near-term comprehension debt rate.
2. Open your most recent architecture decision record. Note the date. If it is more than six weeks old in a team shipping daily, you are accumulating intent debt at the documentation layer faster than you are paying it down.
3. List the constraints currently active in your service: performance budgets, privacy commitments, accessibility requirements, security invariants, and regulatory thresholds. Check which are captured in artifacts that agents can consult versus those held only in someone's memory. Anything in heads alone is a cognitive debt risk; anything missing from artifacts is an intent debt risk.
4. Run a transactive memory check. Ask each engineer who else on the team understands the area they own most deeply. If the answer is no one, that is cognitive debt at the bus-factor level, and it is the most expensive form to remediate after the fact.
5. Review the last three incidents. Identify which were caused by code behaving as written but not as intended. That ratio is your intent debt fingerprint, and it is typically under-reported because incident reviews focus on the proximate cause rather than the missing specification.
6. Audit your most recent five AI agent failures. Count how many resulted from missing rationale rather than missing capability. Reclassifying capability failures as intent debt incidents changes which intervention reduces them.
7. Calculate the mean time to explain for the most recent significant AI-generated module: how long does a senior engineer need to reconstruct its reasoning? Anything beyond twenty minutes signals comprehension debt at the boundary; anything beyond an hour is structural.
8. Examine your onboarding metrics for the last two new hires. Time to first meaningful contribution beyond expected ranges suggests the team's shared theory of the system is no longer transmissible at an acceptable cost. The same metric measures whether new agents can be onboarded cheaply.
9. Survey your senior engineers anonymously: Do you feel less able to predict the system's behaviour than you did six months ago? A consistent yes signals cognitive debt accumulation that no static analysis tool will detect.
10. Map intent capture in your current sprint planning. If decisions are made in meetings and not externalised into ADRs, behaviour-driven specifications, or agent-readable instructions before code is generated, intent debt is being created in real time, and you have not yet built the practice that pays it down.
11. Track your agent-to-engineer ratio. Above approximately three to one (Russo, 2026), individual-agent metrics become unreliable as guides to system behaviour, and the diagnostic items above need to be run at a higher cadence rather than monthly.
Next moves
For the builder
When reviewing AI-generated code, separate two judgments explicitly: did the output satisfy the test, and can I reconstruct the decision logic? Record both. Approving of the first without the second is the operational definition of contributing to comprehension debt, and the cognitive surrender pattern documented by Shaw and Nave (2026) means you will tend to feel more confident than the evidence warrants. Build the discipline of writing decision rationale into commit messages and architecture decision records before merging significant AI-generated changes; capture the why alongside the what. When using AI agents directly, rewrite agent instructions whenever clarification rounds exceed two: the failure point is the missing intent, not the model. Treat your own personal review-without-reproduction ratio as a leading indicator of the comprehension debt you are personally contributing to the codebase.
For the manager
Introduce a cadenced practice that explicitly targets cognitive debt. Storey calls these system walkthroughs: sessions where one engineer narrates a part of the system to others, including parts they did not write. The practice rebuilds the team's transactive memory without waiting for an incident to force the rebuilding, and Naur (1985) suggests it is the only mechanism that genuinely transfers the theory of the system rather than its surface artifacts. Reframe code review as theory transmission, not just defect detection: a review that catches a bug while leaving the reviewer unable to reconstruct the change's reasoning has solved one problem and worsened another. Track the ratio of decisions captured in ADRs versus decisions made in meetings; that ratio is your intent capture rate, and it is the leading indicator of whether your team is building agent-readable artifacts or only agent-consumable code. Watch your on-call escalation rate as a primary signal of emergent system behaviour rather than as a measure of individual engineer competence.
For the roadmap owner
The Triple Debt Model implies that the metrics most organisations report on AI adoption are partial by construction. Productivity gains in code generation should be reported alongside three corresponding indicators: cognitive debt (mean time to explain, on-call escalation trends, senior-engineer confidence), intent debt (rationale capture rate, ADR currency, agent clarification round counts), and the agent-to-engineer ratio that conditions all three. Commission an audit that maps your AI governance framework against these layers, not against generic risk taxonomies; existing frameworks designed for individual model evaluation do not surface the team-level erosion that produces operational risk. Budget for measurement infrastructure at the cognitive and intent layers before scaling agent deployment further. The Storey (2026) and Russo (2026) frameworks together suggest that organisations that scale agent counts without instrumenting these layers will see initial productivity gains followed by a delayed but predictable rise in incident severity, with the lag obscuring the causal relationship for long enough that the original adoption decision is rarely revisited.
Closing thought
The story most boards are being told about AI-assisted software development is a story about cleaner code shipped faster. The story Storey and Russo together describe is more relevant but harder to manage. Software risk is migrating up the abstraction stack, from the code layer where decades of tooling have accumulated, into the team's shared understanding and the rationale captured in artifacts, where most organisations have nothing comparable in place. The teams that recognise this redistribution early will build the instruments before they need them; the teams that do not will discover the accumulation through incidents whose causes are easy to misattribute to the agents themselves.
Daniel Russo, Ph.D., is a Professor of Software Engineering whose research examines the intersection of human cognition and artificial intelligence. Through "Software Insights," he translates empirical research into actionable guidance for software practitioners and organizations.
If this issue surfaces a problem your organisation has been trying to name, I work with engineering leaders to diagnose exactly that kind of challenge, using the same methods behind the research you just read. No frameworks. No opinion without evidence.
danielrusso.org/advisory
References
Cunningham, W. (1993). The WyCash portfolio management system. ACM SIGPLAN OOPS Messenger, 4(2), 29-30.
Curtis, B., Krasner, H., & Iscoe, N. (1988). A field study of the software design process for large systems. Communications of the ACM, 31(11), 1268-1287.
Hou, X., Zhao, Y., Liu, Y., Yang, Z., Wang, K., Li, L., Luo, X., Lo, D., Grundy, J., & Wang, H. (2024). Large language models for software engineering: A systematic literature review. ACM Transactions on Software Engineering and Methodology, 33(8), 1-79.
Hutchins, E. (1995). Cognition in the wild. MIT Press.
Kosmyna, N., Wong, B. R. P., Hauptmann, E. C., Yuan, Y. T. A., Kosmyna, V., & Maes, P. (2026). Your brain on ChatGPT: Accumulation of cognitive debt when using an AI assistant for essay writing. arXiv:2601.00856.
Kruchten, P., Nord, R. L., & Ozkaya, I. (2012). Technical debt: From metaphor to theory and practice. IEEE Software, 29(6), 18-21.
Naur, P. (1985). Programming as theory building. Microprocessing and Microprogramming, 15(5), 253-261.
Peng, S., Kalliamvakou, E., Cihon, P., & Demirer, M. (2023). The impact of AI on developer productivity: Evidence from GitHub Copilot. arXiv:2302.06590.
Russo, D. (2026). More is different: Toward a theory of emergence in AI-native software ecosystems. arXiv:2604.19827.
Shaw, J., & Nave, R. (2026). How AI is reshaping human reasoning and the rise of cognitive surrender. SSRN 6097646.
Storey, M.-A. (2026). From technical debt to cognitive and intent debt: Rethinking software health in the age of AI. arXiv:2603.22106.
Wegner, D. M. (1987). Transactive memory: A contemporary analysis of the group mind. In B. Mullen & G. R. Goethals (Eds.), Theories of group behavior (pp. 185-208). Springer.
Date
05/05/2026