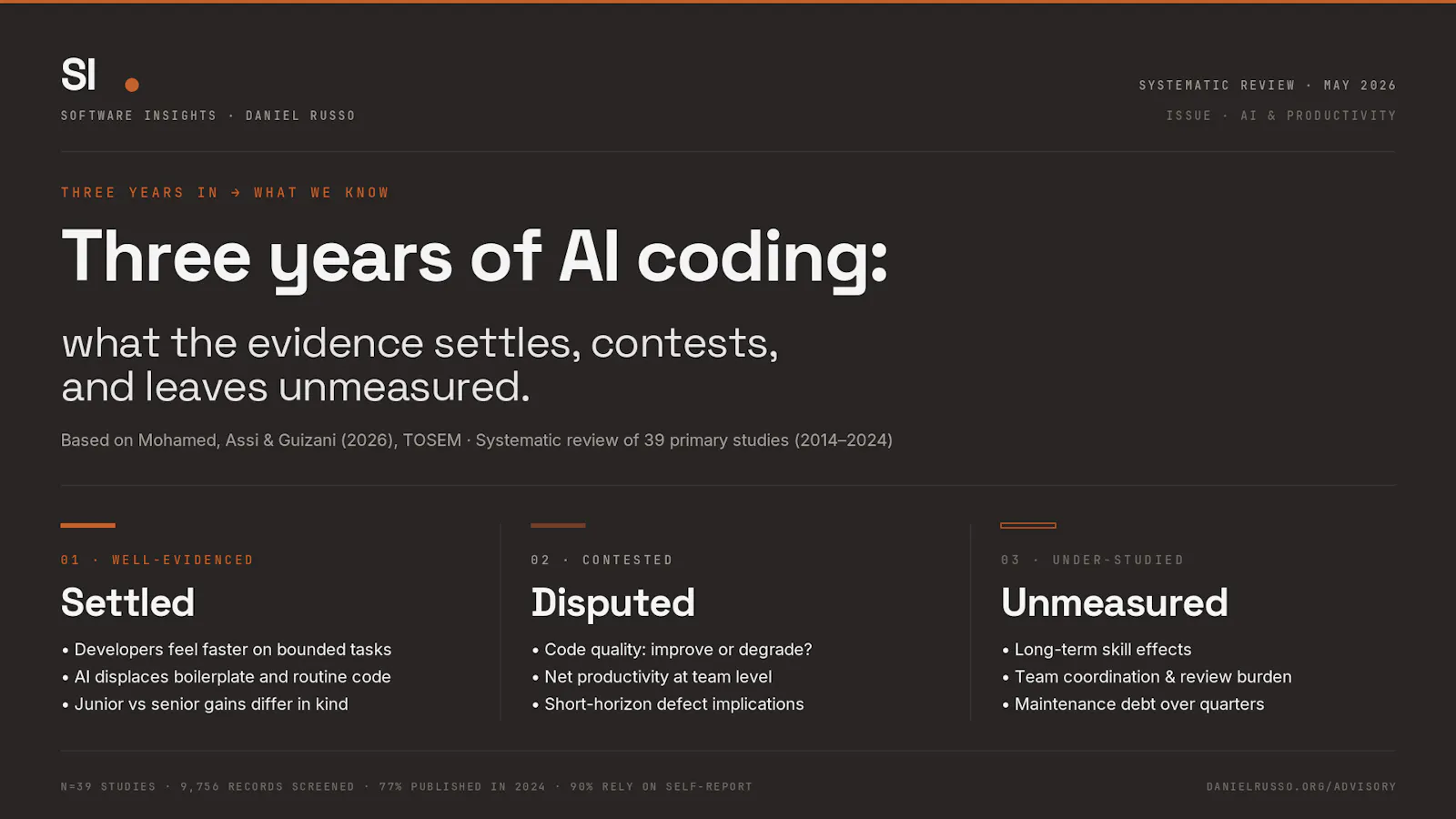
After three years of GenAI adoption in software engineering, the empirical literature has stabilised enough to do something the field could not do a year ago: separate the productivity claims that have survived contact with data from the claims that have not, and the claims nobody has yet bothered to test.
A new TOSEM-accepted systematic review by Mohamed, Assi, and Guizani (2026) gives us the cleanest stocktake to date. The authors synthesise 39 peer-reviewed studies on LLM-assistants and developer productivity, drawn from an initial pool of 9,756 records spanning January 2014 through December 2024. Thirty-five of those 39 studies were published after the release of ChatGPT in November 2022. Seventy-seven percent appeared in 2024 alone. The field is, in other words, both younger and noisier than the industry conversation around it would suggest.
This issue is a stocktaking exercise. It asks where the evidence is now hardened, where it is still pulling in opposite directions, and where the questions executives and engineering leaders keep asking in planning meetings have produced almost no published findings at all.
The shape of the map matters. Many of the operational decisions organisations are making right now, headcount planning, vendor renewal, onboarding redesign, tooling consolidation, ride on claims that fall into the contested or under-studied buckets, not the well-evidenced ones. The first useful act is to know which is which.
What the evidence has settled
The well-evidenced cluster centres on perceived speed and the displacement of routine work. Across the 39-study corpus, the most frequently reproduced finding is that developers experience LLM-assistants as accelerators on bounded coding tasks (Mohamed et al., 2026). Ziegler et al. (2022), one of the earliest large-scale Copilot productivity assessments, reported that developers’ self-rated productivity correlated tightly with their suggestion acceptance rate. Liang et al. (2024) extended this to a large multi-product usability survey of professional developers and found that perceived usefulness clusters around three task types: writing boilerplate, recalling syntax, and generating first drafts of well-specified routines.
Three claims have been replicated consistently enough to be treated as evidence.
The first is that developers feel faster on bounded tasks. The self-perception is robust across study designs, languages, and tool families. It is also a self-perception, and Mohamed et al. (2026) note that 90% of the included studies rely on self-reported productivity data. The acceleration claim, therefore, has the same epistemic status as user-satisfaction data: it is real, it is informative, and it is not interchangeable with behavioural measurement.
The second is that AI is genuinely useful for boilerplate. Repetitive scaffolding, standard API calls, regex composition, structured tests, and conventional CRUD patterns are where time-to-completion drops most consistently across the corpus. This finding is unusual in that it survives the transition from lab tasks to field studies relatively intact.
The third is that junior and senior developers benefit differently. Junior engineers report larger absolute speed gains on tasks in unfamiliar territory; senior engineers report smaller absolute gains but place more weight on cognitive offloading and on reduced context-switching to web search (Liang et al., 2024). The differential matters for hiring strategy and onboarding: the same tool produces qualitatively different productivity profiles depending on where the user sits on the experience curve.
These three claims should now be treated as load-bearing in any productivity narrative your organisation builds. The earlier debate about whether developers feel faster at all has effectively closed.
Where the evidence pulls in opposite directions
The contested cluster is narrower but more consequential, and it begins with the question executives most want answered.
Code quality is the marquee dispute. Mohamed et al. (2026) state the position bluntly in their abstract: whether LLM-assistants improve or degrade code quality remains unresolved, with existing studies reporting contradictory outcomes contingent on context and evaluation criteria. Some studies report that AI-generated code increases compliance with style guides and reduces certain classes of trivial typographic errors. Others find elevated rates of unsafe patterns, missing error handling, and silent regressions when generated code is accepted without thorough review. The contradiction reflects genuine sensitivity to which programming language, which task complexity, which evaluation rubric, and which baseline developer experience level the study uses. Two studies can both be methodologically sound and disagree because they are measuring different things under the same word.
The second contested claim is net team productivity. The individual-level perceived-speed finding does not aggregate cleanly to teams. Studies that measure throughput at the squad or pull-request level find smaller, more variable, and sometimes null effects compared with individual self-reports. Whether this is because individual gains are absorbed into review and coordination overhead, or because team-level measurement catches confounds that lab tasks cannot, is unresolved. The systematic review classifies 38% of the corpus as laboratory experiments and only 23% as field studies (Mohamed et al., 2026). The lab-to-team translation is doing more rhetorical work than the data supports.
The third contested claim concerns defect implications under maintenance. Several studies report short-term defect rates that are statistically indistinguishable from baseline. None of them follows the resulting code into a maintenance horizon long enough to observe whether the defect distribution shifts later. This is a problem of study design, not of absence of signal: the field has been operating on observation windows measured in weeks, not quarters.
What we still do not know
The under-studied cluster is the section of the map where the industry has the most confident opinions and the academy has produced the least evidence. The contrast is sharp enough that the systematic review identifies it as the most consequential gap in the field.
While the majority of studies (90%) adopt a multi-dimensional perspective by examining at least two SPACE dimensions, only 15% extend beyond three dimensions, indicating substantial room for more integrated evaluations (Mohamed et al., 2026).
The two SPACE dimensions most consistently underexamined are Communication and Activity (Forsgren et al., 2021). What this means concretely is that the literature has plenty to say about how an individual developer feels after using Copilot for thirty minutes, and almost nothing to say about how a team’s review cadence, merge cycle, and on-call rotation change after six months of adoption.
Four questions sit in this empirical gap and deserve naming.
Long-term skill effects. Whether sustained reliance on LLM-assistants atrophies the foundational capabilities that allow senior engineers to verify generated output is, at present, a hypothesis rather than a finding. Mohamed et al. (2026) catalogue cognitive offloading as a documented risk, but the longitudinal observation required to test the skill-erosion claim does not exist in the published literature.
Team coordination. The SPACE Communication dimension covers exactly the practices most likely to shift as AI authorship becomes routine: pair-programming frequency, asynchronous review patterns, and the way knowledge transfers between senior and junior engineers within a codebase. The review identifies this dimension as underexplored across all 39 studies.
Code review burden. If junior engineers ship more code faster, senior reviewers carry more verification load. No study in the corpus measures this redistribution systematically. The productivity gain reported at the IC level may, in aggregate, be a re-routing of effort up the seniority ladder rather than a net team gain.
Maintenance debt. The cost of accepted but minimally understood code surfaces months later, in incident response, refactor cycles, and the quiet erosion of architectural coherence. Studies in the corpus operate on observation windows too short to detect this signal. Any organisation treating today’s perceived-speed gains as a guarantee of tomorrow’s delivery throughput is making a forecast the literature cannot underwrite.
Why the corpus reads the way it does
Three methodological features of this evidence base shape how much weight any claim should carry, and they apply uniformly across all three buckets.
First, the corpus is recent and concentrated. With 77% of included studies published in 2024 (Mohamed et al., 2026), the field has not had time for replication or for the natural correction process that distinguishes a finding from an artifact. Replication culture in software engineering is already weaker than in adjacent disciplines; in a literature this young, it has barely had time to begin.
Second, self-report dominates. Ninety percent of included studies use self-reported productivity data. Only 15 of 39 use validated instruments such as NASA-TLX, the SPACE questionnaire, or the technology acceptance model (Mohamed et al., 2026). Self-report is not invalid; it is decisive evidence for satisfaction and perception. It is poor evidence for throughput, defect rate, or coordination cost. Confusing the two is the most common rhetorical move in industry productivity narratives.
Third, tool sampling is narrow. ChatGPT (15 studies) and GitHub Copilot (14 studies) account for the majority of the corpus. Tabnine, GPT-4, and CodeWhisperer appear in three studies each; Claude, Codex, Gemini, and roughly a dozen other tools appear once. The generalisation from “Copilot in 2024” to “AI coding tools in 2026” is doing analytical work that the evidence base does not cleanly support. Findings about a specific tool in a specific year carry only as far as the tool and the year.
These caveats do not invalidate the well-evidenced cluster per se; they calibrate the confidence interval around it. Russo (2024) makes a parallel argument from a different angle: that adoption outcomes in software engineering depend on a tight match between tool affordances, individual workflow, and team context, and that the same tool can produce different productivity signatures in different organisations.
A 30-minute drill: which of your AI productivity claims are actually evidenced?
Run this audit in your next planning session. The goal is to locate every productivity claim circulating inside your organisation on the three-bucket map, then to identify which operational decisions are currently sitting on claims the literature does not support.
1. Pull the last six weeks of internal messaging on GenAI productivity. Slack threads, all-hands slides, vendor decks, board updates, internal blog posts. Extract every specific productivity claim. Aim for 15 to 25 claim sentences.
2. For each claim, ask which SPACE dimension it concerns: Satisfaction, Performance, Activity, Communication, or Efficiency. Discard claims that do not map cleanly. They are not falsifiable enough to audit, which is itself a finding.
3. Place each remaining claim into one of three buckets. Well-evidenced if it concerns perceived speed on bounded tasks, boilerplate displacement, or junior-versus-senior productivity differentials. Contested if it concerns code quality, team-level throughput, or short-horizon defect rates. Under-studied if it concerns long-term skill effects, coordination patterns, code review burden, or maintenance debt.
4. Count what is in each bucket. Most organisations find that roughly half of their public productivity claims sit in the contested or under-studied buckets. That ratio is the first useful number the audit produces.
5. For every claim in the contested bucket, write one sentence naming the context contingency: which language, which task complexity, which baseline developer experience, which evaluation rubric. If the claim cannot survive the addition of that sentence, retire it from internal communication until you can.
6. For every claim in the under-studied bucket, name the metric that would, in principle, falsify it. If no metric exists, the claim is rhetoric and should be re-labelled as a hypothesis your organisation is testing, not a finding it relies upon.
7. Identify one operational decision currently riding on a contested or under-studied claim. Headcount planning, vendor renewal, tooling consolidation, hiring criteria, onboarding redesign. That decision is the one most exposed to evidence reversal.
8. Set a six-month re-audit date. The field is publishing fast enough that the three buckets will move within two cycles. Build the re-audit into your roadmap review cadence so the map updates as the evidence does.
The output of the drill is a single page with three columns of claim statements, one operational decision flagged for sensitivity testing, and a re-audit date. That single page is more rigorous than most AI productivity narratives currently in circulation.
Next moves
For the Builder
1. Track your suggestion acceptance rate alongside the time you spend correcting accepted suggestions. The first number is what tool marketing optimises for. The second is the one Ziegler et al. (2022) treat as decisive. The ratio of the two is your honest personal productivity signal.
2. Separate your speed gain on boilerplate from your speed gain on novel logic. The first is reproducible across studies and across people. The second varies by task complexity and is where your professional judgment still does the most work. Conflating the two leads to overconfidence in exactly the situations where LLM output is most likely to mislead.
3. Add a verification step to your workflow that does not depend on the model. A failing test written before generation, a static-analysis pass after generation, or a peer review on any function above a chosen complexity threshold. The cognitive offloading risk catalogued by Mohamed et al. (2026) is mitigated by routine, not by vigilance.
For the Manager
1. Build a team-level dashboard that pairs SPACE Performance and SPACE Efficiency with at least one Communication metric. Review cycle time, pair-programming frequency, or knowledge-transfer signal. The literature has shown that Performance and Efficiency improve in isolation; whether your team’s coordination layer is paying the bill is a question your dashboard, not the literature, must answer.
2. Run a quarterly code review burden check. Compare the volume and complexity of changes submitted by junior engineers against the time senior reviewers spend on them. If the second number is climbing faster than the first, the productivity gain is being redistributed inside the team, not realised by it.
3. Protect time for non-AI authorship in onboarding. The long-term skill effect is the hypothesis with the weakest empirical base and the largest organisational consequences. A six-month onboarding rotation that includes at least one project written without LLM assistance is cheap insurance against a risk the literature cannot yet measure.
For the Roadmap Owner
1. Move productivity reporting from individual perception to team-level outcome. The acceleration claim is well-evidenced at the individual level and contested at the team level. Reporting only the first overstates the second, and overstating the second is how organisations make irreversible headcount and tooling decisions on reversible evidence.
2. Fund a longitudinal observation capability. A code provenance log that tags AI-assisted commits, then surfaces defect, refactor, and incident rates against that tag at twelve and twenty-four months. This is the measurement infrastructure the academic field does not yet have, and building it inside your own organisation will outpace the publication cycle by years.
3. Tie tool vendor renewal to a written claim audit. Ask which of the vendor’s stated benefits sit in the well-evidenced bucket, which in the contested bucket, and which in the under-studied bucket. The conversation that follows is the first one most organisations have ever had with a GenAI vendor on empirical terms. It is also the one most likely to reset the contract.
Closing thought
The honest summary of three years is that perceived speed has hardened into evidence, code quality has hardened into a controversy, and almost everything that matters at the team and maintenance horizon is still a hypothesis. Most operational decisions about AI coding tools currently rest on the second and third categories. Which of the productivity claims your leadership team repeats most often would survive the 30-minute drill in your next planning session?
Daniel Russo, Ph.D., is a Professor of Software Engineering whose research examines the intersection of human cognition and artificial intelligence. Through “Software Insights,” he translates empirical research into actionable guidance for software practitioners and organizations.
If this issue surfaces a problem your organisation has been trying to name, I work with engineering leaders to diagnose exactly that kind of challenge, using the same methods behind the research you just read. No frameworks. No opinion without evidence.
danielrusso.org/advisory (Opens in a new window)
References
Forsgren, N., Storey, M.-A., Maddila, C., Zimmermann, T., Houck, B., & Butler, J. (2021). The SPACE of developer productivity: There’s more to it than you think. ACM Queue. https://doi.org/10.1145/3454122.3454124 (Opens in a new window)
Liang, J. T., Yang, C., & Myers, B. A. (2024). A large-scale survey on the usability of AI programming assistants: Successes and challenges. In Proceedings of the 46th IEEE/ACM International Conference on Software Engineering (ICSE ’24). IEEE/ACM.
Mohamed, A. (2026). The impact of LLM-assistants on software developer productivity: A systematic review and mapping study. ACM Transactions on Software Engineering and Methodology. Advance online publication. https://doi.org/10.1145/3809494 (Opens in a new window)
Russo, D. (2024). Navigating the complexity of generative AI adoption in software engineering. ACM Transactions on Software Engineering and Methodology, 33(8), Article 221, 1–5. https://doi.org/10.1145/3652154 (Opens in a new window)
Ziegler, A., Kalliamvakou, E., Li, X. A., Rice, A., Rifkin, D., Simister, S., Sittampalam, G., & Aftandilian, E. (2022). Productivity assessment of neural code completion. In Proceedings of the 6th ACM SIGPLAN International Symposium on Machine Programming (MAPS ’22) (pp. 21–29). ACM.
Date
May 19, 2026