The central failure of AI evaluation today is not that organizations test too little. It is that they test with instruments they have never validated.
Every engineer who has ever participated in a tool selection process for AI-assisted development has encountered benchmark scores. Models are compared on HumanEval, SWE-bench, or some proprietary internal suite. Procurement decisions follow from those comparisons. Leadership asks which tool "scores highest." The benchmark has become the evidence base for adoption decisions that affect team cognition, code quality, and engineering culture. The question nobody asks loudly enough is whether the benchmark measures what it claims to measure.
In a systematic review of 445 LLM benchmarks published at leading machine learning and natural language processing conferences, Bean et al. (2025) found that nearly every reviewed benchmark had weaknesses in at least one dimension of construct validity. Construct validity, a concept originating in psychological measurement (Cronbach & Meehl, 1955), refers to the degree to which a test score provides evidence for claims about the target phenomenon. A benchmark with high construct validity actually measures the capability it claims to measure. Most of the benchmarks currently driving AI adoption decisions in software engineering do not meet this standard, not because researchers are careless, but because the field has not yet developed the shared standards that rigorous measurement requires.
The argument in this article is specific: given the volume of organizational decisions now anchored to benchmark scores, a poorly designed benchmark causes more harm than no benchmark at all. It creates false certainty. And in an environment where engineering leaders, managers, and practitioners act on performance numbers, false certainty is operationally dangerous. The number that ends the evaluation process is not a fact but a proxy, and most proxies in use today are poorly constructed.
When the thing being measured has no agreed-upon definition
Construct validity begins before a single task is designed or a single prompt is written. It begins with the phenomenon: the capability or behavior the benchmark is intended to measure. If that phenomenon is not defined precisely, the benchmark cannot be validated against it. Thus, it determines whether the number at the end of the evaluation process refers to anything stable in the world.
Bean et al. (2025) found that 21.7% of the 445 reviewed benchmarks provided no definition of their target phenomenon at all. A further 47.8% of those that did provide a definition targeted phenomena whose meaning is actively contested in the research community. That means roughly half of the reviewed benchmarks are measuring something whose conceptual boundaries nobody has formally agreed on. "Alignment" is the paradigm case: benchmarks claiming to measure alignment frequently operationalize contested sub-concepts such as "harmlessness" without specifying which of the competing definitions they apply. A high score on such a benchmark does not tell you that a model is aligned. What it tells you is that the model performed well on one implicit operationalization of a concept that the field disputes.
The composite-phenomena problem compounds this. Bean et al. (2025) found that 61.2% of reviewed benchmarks target phenomena that consist of sub-components rather than a single unified capability. An "agentic capability" benchmark might combine intent recognition, structured output generation, and alignment checking into a single aggregate score. That score cannot tell you which sub-component a model succeeds or fails on. For a software engineering team adopting an AI coding assistant, this gap has direct consequences: a tool that performs well at structured output but fails at intent recognition will produce syntactically clean code that misunderstands what the developer asked for. The composite score will not flag this.
In software engineering evaluation, the standard capability categories follow the same pattern. "Code generation quality" routinely aggregates functional correctness, security posture, maintainability, and documentation quality into a single number. A benchmark that reports one score for "code generation" is likely capturing test-passing functional correctness and little else. Every other dimension of quality that software engineering practice actually requires is unmeasured, unreported, and invisible to the adoption decision.
How sampling decisions and metric choices contaminate the number
Even a well-defined phenomenon can produce misleading benchmark scores if the tasks used to measure it are not representative, or if the scoring method fails to track the thing that matters.
Bean et al. (2025) found that 39.3% of reviewed benchmarks relied at least partially on convenience sampling, selecting task items because they were accessible rather than because they were systematically representative of the target capability space. A further 38.2% reused items from prior benchmarks or human examinations without adjusting for the validity problems those sources carry. Bean et al. (2025) offer a precise illustration: the AIME mathematics examination was designed for hand calculation, so its numbers were specifically chosen to remain arithmetically tractable. An LLM benchmark built on AIME items will systematically undertest the capability that actually distinguishes models in practice, which is performance on larger numbers where LLM arithmetic tends to fail. The benchmark does not measure arithmetic ability as it occurs in real deployment; it measures performance on a human examination that was never designed to probe LLM weaknesses.
A further 31.2% of reviewed benchmarks generated task items using LLMs themselves (Bean et al., 2025). This introduces a circularity that undermines validity in a specific way: LLM-generated items reflect the distributional tendencies of the generating model, which are not necessarily representative of the full capability space, and may systematically avoid the edge cases where the evaluated model fails. A benchmark that an LLM helped design may be easier for LLMs to pass than one designed by domain experts with access to known failure modes.
The scoring layer amplifies the problem. Exact matching was used at least partially in 81.3% of reviewed benchmarks and served as the exclusive metric in 40.7% of them (Bean et al., 2025). Exact matching is computationally convenient and requires no human judgment. It is also a thin proxy for most software engineering capabilities. Whether a model produces output that matches a reference string is not the same question as whether the model's output is correct, secure, readable, or well-tested in a real codebase. A code generation model that scores 90% on an exact-match benchmark may produce consistently poor code in deployment because the benchmark never asked whether the code was maintainable or free of security vulnerabilities.
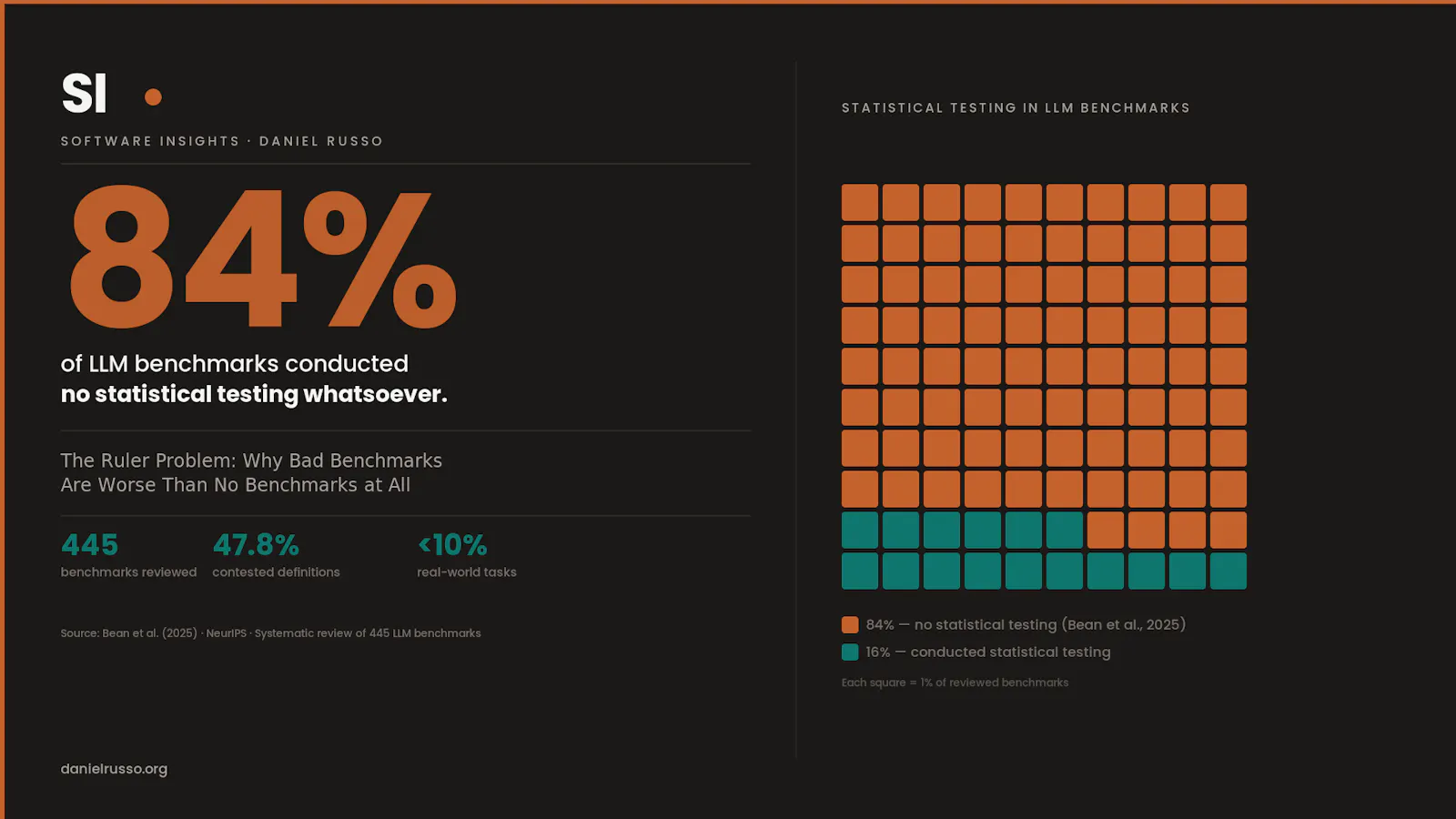
The most striking figure in the entire review concerns statistical inference:
"At present, only 16.0% of reviewed benchmarks conducted any statistical testing." (Bean et al., 2025)
Eighty-four percent of benchmarks currently cited in research papers, used to select AI tools, and referenced in product comparisons, contain no uncertainty quantification. A model that scores 73.1% on a benchmark and a competitor that scores 72.3% are reported as having different scores, but no analysis determines whether that difference is stable, replicable, or statistically distinguishable from noise. The field routinely ranks models by numbers it has not tested for significance, then uses those rankings to direct research effort and justify adoption decisions worth considerable organizational investment.
When the score and the claim no longer correspond
The final layer of the construct validity problem is the gap between what a benchmark actually measures and what researchers claim it measures. Bean et al. (2025) found that only 53.4% of reviewed benchmarks included any evidence that the benchmark is a valid measure of the phenomenon it claims to assess. Nearly half of the published LLM benchmarks do not attempt to justify the inferential chain from score to capability claim.
In clinical diagnostics, this failure mode has a precise name. A diagnostic test with poor specificity generates false positives. A blood glucose meter that reads 15% above actual values does not fail neutrally: patients with diabetes appear better controlled than they are, physicians reduce insulin doses, and patients deteriorate. The instrument actively replaces accurate uncertainty with confident error. Clinical epidemiologists formalized this logic decades ago: a test whose likelihood ratio approaches 1 provides no information, but a test with negative predictive value causes harm by displacing the careful judgment that would have operated in its absence. The instrument does not merely fail to help, but it makes decisions worse because it makes false confidence seem warranted.
Software benchmarks operate under the same logic when construct validity is low. An organization that selects an AI code review assistant based on a benchmark using convenience-sampled tasks, exact-match scoring, no statistical testing, and no validity justification has purchased a number. When that number fails to predict real performance on real code, the organization rarely concludes that the benchmark was the problem. It concludes that AI is unpredictable, or that the model was overhyped. The benchmark has not merely measured the wrong thing; it has made rigorous evaluation feel like it was already done.
The case against relying on a poorly designed benchmark, rather than conducting no formal benchmark at all, follows directly from how decisions work under uncertainty. An organization with no performance data knows it is uncertain and calibrates its confidence accordingly. An organization with an invalid benchmark score believes it has resolved that uncertainty. The second organization will make worse decisions with greater confidence. That is the condition a bad instrument reliably produces, and it is the reason the choice between a valid benchmark and no benchmark is not symmetric with the choice between any benchmark and no benchmark.
What a valid benchmark actually requires
Bean et al. (2025) provide eight recommendations for improving construct validity in LLM benchmarks. Applied to the practitioner context, they reduce to a set of questions any team should ask before relying on a benchmark score:
1. Is the phenomenon explicitly defined? If the benchmark paper does not specify what is being measured and what the definition excludes, the score has no interpretable reference point.
2. Is the task ecologically valid? Fewer than 10% of reviewed benchmarks used complete real-world tasks. If the benchmark task does not resemble how a model is actually deployed, the score may not transfer to production.
3. Was the sampling principled? Convenience sampling, present in 39.3% of reviewed benchmarks, selects for availability rather than representativeness. Check whether the benchmark paper describes a systematic sampling rationale.
4. Does the metric capture the phenomenon? Exact matching, the dominant metric in 81.3% of benchmarks, measures string identity, not capability. Identify which metric was used and what it leaves unmeasured.
5. Are uncertainty estimates reported? A benchmark without confidence intervals or significance tests cannot determine whether a score difference between models is real or an artifact of sampling variance.
6. Was contamination checked? If benchmark test items appear in common LLM pretraining corpora, the score measures memorization rather than capability. Recommend canary strings and held-out item sets for ongoing verification.
7. Is there an error analysis? A valid benchmark should characterize failure modes. Without an error typology, it is not possible to determine whether a model fails because of the target phenomenon or because of a confounding task.
8. Is the validity claim explicit? The benchmark paper should articulate why this task, scored by this metric, supports claims about this phenomenon. In 46.6% of reviewed benchmarks, it does not.
Next moves
For the builder
• Before treating any benchmark score as evidence for a tooling decision, check the benchmark's original paper against the eight criteria above. Fewer than five criteria satisfied should substantially reduce your confidence in the score.
• Construct a small evaluation set from your actual codebase, using tasks that reflect real engineering work. A model that scores well on a published benchmark but poorly on your representative tasks is giving you accurate information that no leaderboard can provide.
• When a model provider cites a benchmark score in documentation or marketing material, identify which metric was used. An exact-match score on a multiple-choice dataset carries substantially less information about production behavior than an ecologically valid evaluation on realistic tasks.
• Log cases where AI output failed in ways the cited benchmark would not have predicted. Over time, this produces a calibration record more relevant to your context than any published leaderboard score.
For the manager
• Establish a team norm: before any benchmark score enters a tooling or adoption discussion, someone must describe what the benchmark actually measures and what it does not. This takes two minutes and filters a common category of procurement error.
• When commissioning internal evaluations of AI tools, define the evaluation criteria before any tool is tested. Post-hoc criteria are susceptible to the same construct validity failures as published benchmarks, without the peer review.
• Treat score differences of one or two percentage points between models as noise until uncertainty estimates indicate otherwise. Without reported variance, small score differences are not reliable signals of capability differences.
• Run a structured pilot in which your team evaluates tools on a sample of actual work tasks from the past quarter. Ecological validity, the correspondence between the evaluation context and the deployment context, is the dimension most consistently absent from published benchmarks and most directly within your control.
For the roadmap owner
• When AI adoption strategy references benchmark comparisons, require that the benchmarks cited satisfy explicit construct validity criteria before they enter the decision framework. This is a policy decision, not a technical one, and it filters a significant source of strategic noise from your investment logic.
• Invest in building internal evaluation datasets that reflect your organization's specific engineering context. Published benchmarks are designed for general use cases. A modest investment in task collection and annotation produces instruments with far higher relevance than any public leaderboard for your deployment needs.
• When contracting with AI vendors, include benchmark validity as a due diligence item. Ask specifically which benchmarks are cited, what statistical testing was performed, whether contamination was checked, and whether real-world tasks were used for validation. The quality of the answers will indicate whether the vendor understands the limits of its own evidence.
• Treat benchmark scores in the same category as any other performance claim subject to audit. A vendor score on a benchmark with unknown construct validity carries the same evidential weight as a self-reported customer satisfaction figure with no disclosed methodology. High-stakes decisions warrant independent verification.
Closing thought
Benchmarks are not neutral instruments. They encode assumptions about what matters, which tasks represent real capability, and what performance levels constitute evidence. Those assumptions are rarely made explicit, and current publication norms in AI research do not require them to be. The practical consequence is that practitioners relying on benchmark scores to make adoption decisions are frequently acting on numbers that were never validated for the inferences those decisions require.
The question worth bringing back to your engineering organization is not "what score does this tool get?" but "on what task, with what metric, under what sampling assumptions, and with what statistical confidence?" The gap between those two questions is where most AI adoption decisions are currently made. How many of the eight validity criteria does the benchmark at the center of your next tool evaluation actually satisfy?
Daniel Russo, Ph.D., is a Professor of Software Engineering whose research examines the intersection of human cognition and artificial intelligence. Through "Software Insights," he translates empirical research into actionable guidance for software practitioners and organizations.
If this issue surfaces a problem your organisation has been trying to name, I work with engineering leaders to diagnose exactly that kind of challenge, using the same methods behind the research you just read. No frameworks. No opinion without evidence.
danielrusso.org/advisory (Si apre in una nuova finestra)
References
Bean, A. M., Kearns, R. O., Romanou, A., Hafner, F. S., Mayne, H., Batzner, J., Foroutan, N., Schmitz, C., Korgul, K., Batra, H., Deb, O., Beharry, E., Emde, C., Foster, T., Gausen, A., Grandury, M., Han, S., Hofmann, V., Ibrahim, L., Kim, H., Kirk, H. R., Lin, F., Liu, G. K.-M., Luettgau, L., Magomere, J., Rystrøm, J., Sotnikova, A., Yang, Y., Zhao, Y., Bibi, A., Bosselut, A., Clark, R., Cohan, A., Foerster, J., Gal, Y., Hale, S. A., Raji, I. D., Summerfield, C., Torr, P. H. S., Ududec, C., Rocher, L., & Mahdi, A. (2025). Measuring what matters: Construct validity in large language model benchmarks. 39th Conference on Neural Information Processing Systems (NeurIPS 2025), Datasets and Benchmarks Track.
Cronbach, L. J., & Meehl, P. E. (1955). Construct validity in psychological tests. Psychological Bulletin, 52(4), 281-302.
Data
12/05/2026